

In a major leap forward for containerized infrastructure, Amazon Web Services (AWS) has officially unveiled a significant enhancement to Amazon Elastic Container Service (ECS) service auto scaling. By introducing support for high-resolution, 20-second metrics, AWS is drastically reducing the latency between traffic spikes and infrastructure adjustments. This update marks a paradigm shift for businesses operating dynamic, high-traffic microservices, promising a more responsive, cost-efficient, and resilient cloud environment.
The Core Innovation: Bridging the Gap in Real-Time Scaling
For years, Amazon ECS has been the bedrock of container orchestration for thousands of enterprises, providing robust mechanisms for scaling tasks based on demand. Historically, service auto scaling relied on standard CloudWatch metrics, which operate on a 60-second resolution. While sufficient for many steady-state workloads, this one-minute interval created a "blind spot" for applications experiencing sudden, explosive traffic bursts.
The new update addresses this by enabling 20-second high-resolution metrics. By tripling the frequency of data points collected, ECS can now detect performance bottlenecks or demand surges with significantly greater precision. This shift is not merely an incremental improvement; it is a fundamental reconfiguration of how Amazon ECS communicates with the Application Auto Scaling service, allowing for a near-instantaneous response to real-world performance telemetry.
A Chronology of AWS Container Scaling Evolution
To understand the magnitude of this update, one must look at the trajectory of Amazon ECS scaling capabilities.
The Foundation: Reactive and Proactive Models
In its early stages, ECS scaling was primarily reactive, relying on target tracking to maintain performance thresholds. As the platform matured, AWS introduced predictive scaling—leveraging sophisticated machine learning algorithms to analyze historical traffic patterns and preemptively provision capacity before demand peaked.
The Middleware Transition
The integration of Scheduled Scaling allowed businesses with predictable, time-based traffic—such as e-commerce platforms during holiday sales or news sites during major events—to plan capacity in advance. However, the "unpredictable" burst remained a challenge for systems engineers, who often had to over-provision resources just to ensure they could survive a sudden, unplanned spike.
The 20-Second Breakthrough
The current announcement follows months of internal benchmarking and infrastructure optimization. By refining the metric publishing pipeline and optimizing the feedback loop between CloudWatch and the ECS scheduler, AWS has successfully moved the needle from "near real-time" to "true real-time" elasticity. This rollout represents the culmination of a multi-year effort to reduce cold-start latency and improve the agility of containerized workloads across AWS Fargate, EC2, and managed instances.
Supporting Data: Quantifying the Performance Gain
The impact of this update is best illustrated through the empirical data provided by AWS’s recent benchmarking tests. In the world of cloud infrastructure, seconds translate directly into user experience—and ultimately, revenue.

According to official AWS performance metrics, the improvement in responsiveness is stark:
- Time to Trigger Scale-Out: The interval from the initial traffic spike to the triggering of a scale-out event has plummeted from 363 seconds to a mere 86 seconds. This represents a 76% improvement in speed, or effectively 4.2 times faster than the previous configuration.
- Total Provisioning Latency: Perhaps more critical is the total time required to scale and fully provision new tasks. This metric has seen a reduction from 386 seconds to 109 seconds, marking a 72% improvement (3.5x faster).
These figures suggest that an application facing a sudden "thundering herd" of traffic will now have its new capacity ready in under two minutes, whereas previously, it would have been struggling for over six minutes. For high-throughput services, this reduction in latency is the difference between seamless performance and a potential system outage or dropped requests.
Implementation: Integrating Faster Scaling into Your Architecture
The transition to high-resolution scaling is designed to be seamless, though it requires specific configuration steps.
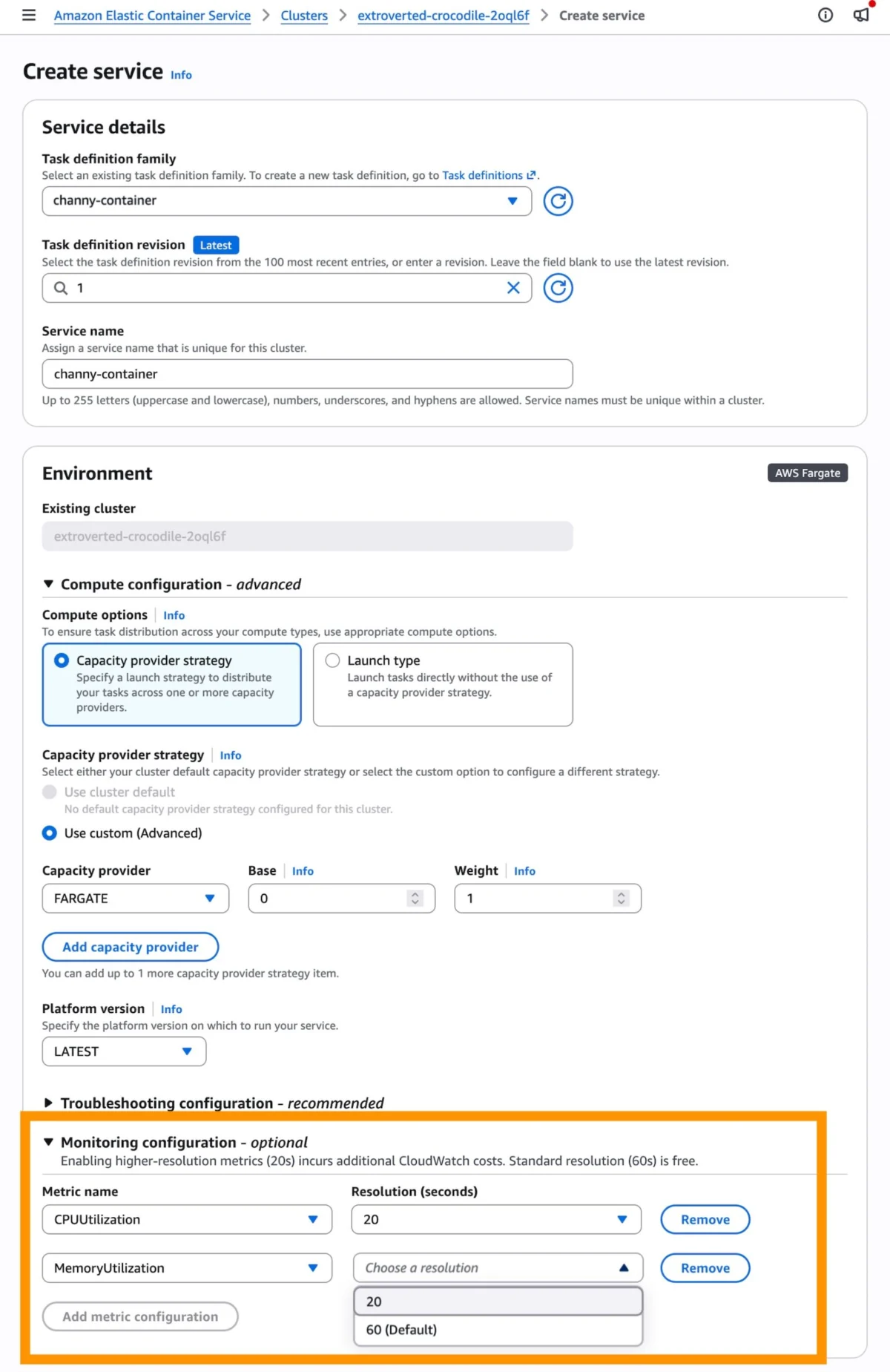
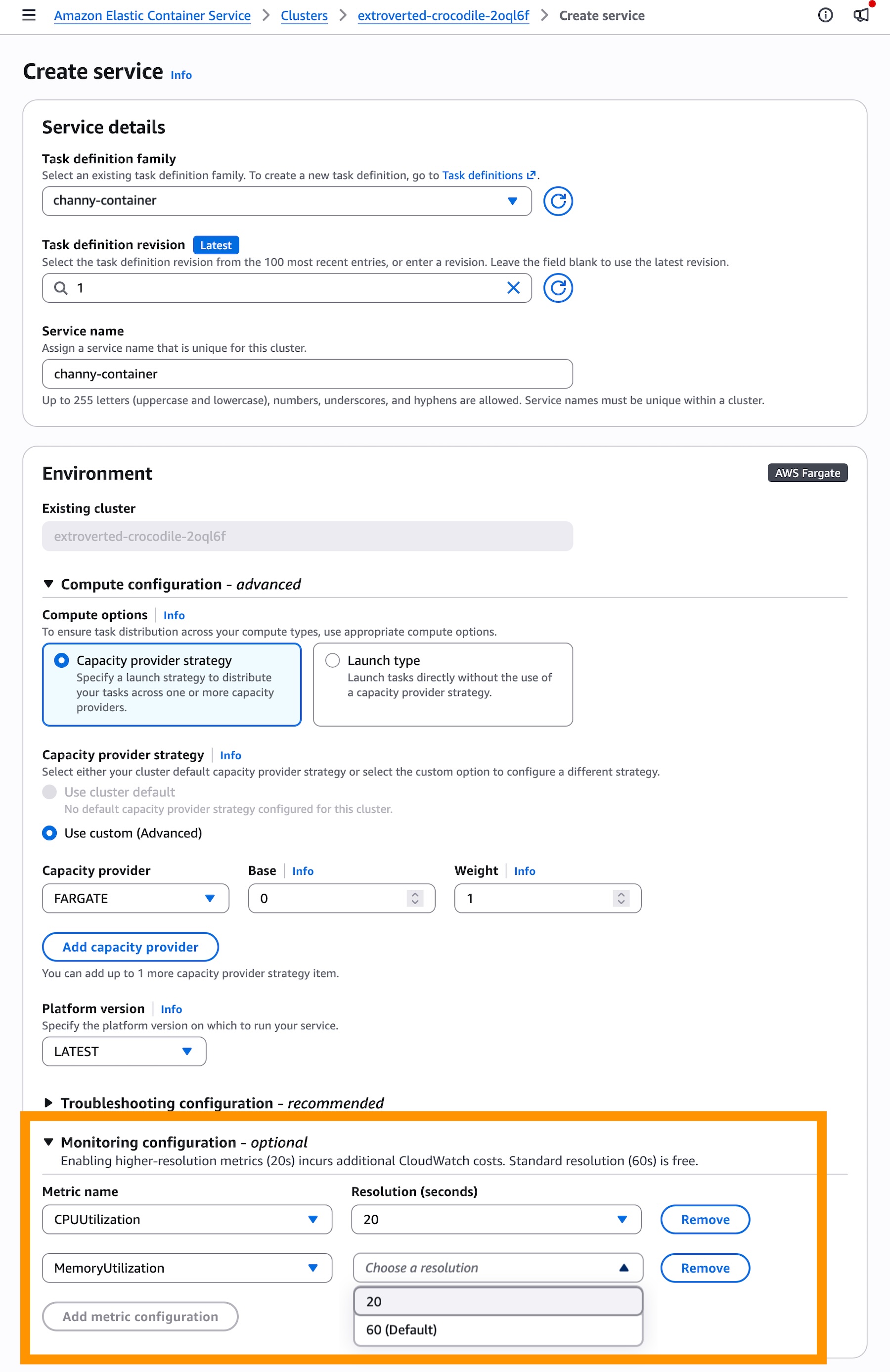
Enabling High-Resolution Metrics
To activate this feature, users must opt-in via the Amazon ECS console, AWS SDKs, or CloudFormation. When creating or updating a service, the "Monitoring configuration" section now offers the option to enable 20-second metrics.
Setting Up Target Tracking
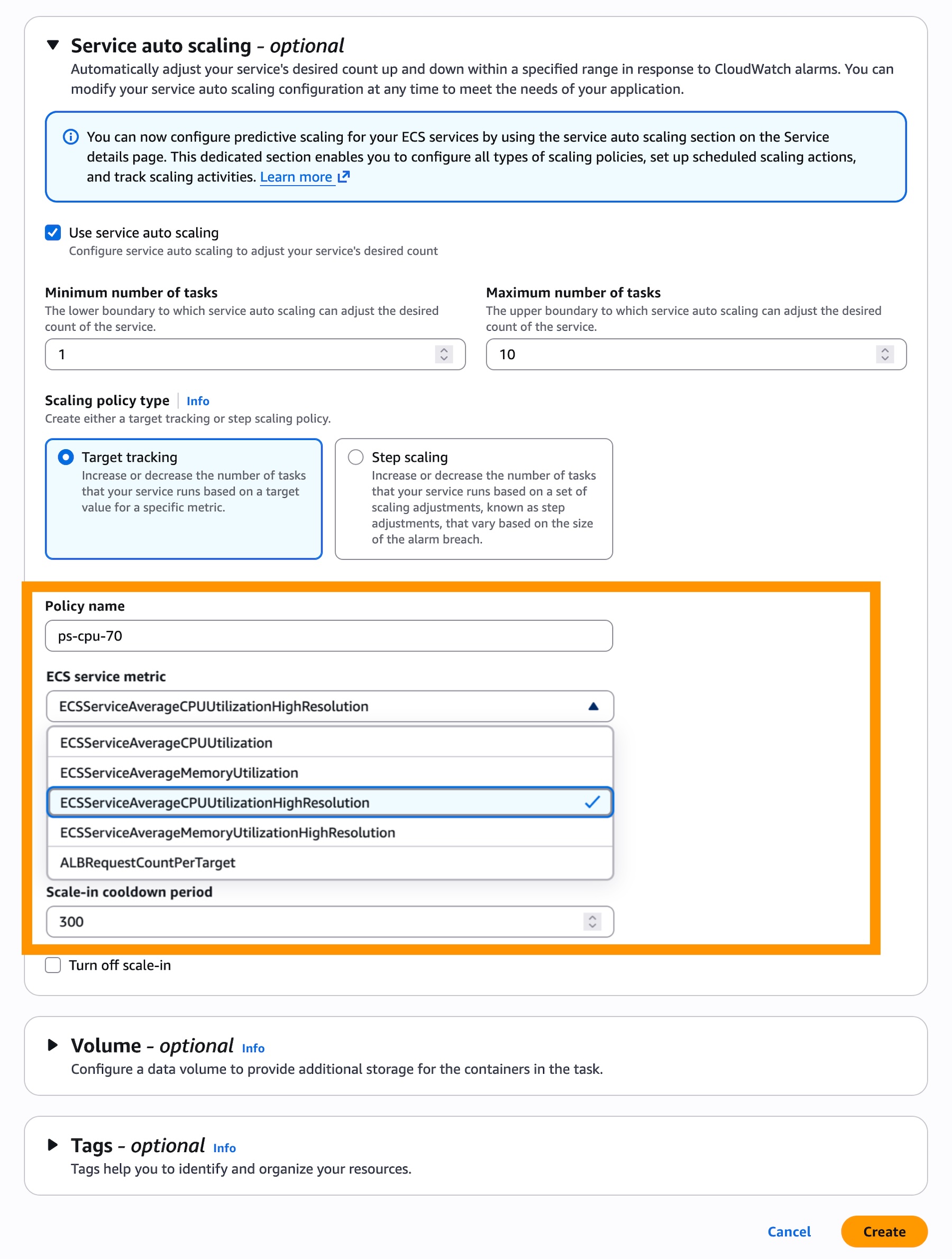
Once high-resolution metrics are active, engineers can configure a target tracking scaling policy. By selecting ECSServiceAverageCPUUtilizationHighResolution or ECSServiceAverageMemoryUtilizationHighResolution, the ECS scheduler shifts from the standard 60-second cycle to the high-resolution interval.
Deployment Considerations
It is important to note that while the feature itself is free, the high-resolution metrics incur additional CloudWatch costs. Organizations should weigh the cost-to-performance ratio carefully. For critical production workloads, the cost is likely negligible compared to the benefits of increased stability. However, for non-critical, development, or testing environments, the standard 60-second resolution remains a cost-effective default.
Official AWS Perspective and Strategic Implications
In his announcement, Channy Yun, a leading voice at AWS, emphasized that this update is a direct response to customer feedback. Developers have long requested more granular control over scaling triggers, particularly as applications have become more distributed and sensitive to latency.
The "Elasticity-as-a-Service" Mandate
This release reinforces the broader AWS philosophy: "Elasticity is the greatest advantage of the cloud." By removing the barriers of time-lagged scaling, AWS is empowering developers to build applications that feel virtually "infinite." This is particularly relevant for the rise of generative AI inference workloads, which often require instantaneous spikes in compute power to serve user prompts in real-time.
Architectural Implications
- Reduced Over-Provisioning: With faster scaling, businesses no longer need to maintain as much "headroom" (excess idle capacity) to guard against sudden spikes. This directly translates to lower operational expenditure (OpEx).
- Enhanced Reliability: The reduction in the "vulnerability window"—the time between a surge and the provision of new resources—significantly lowers the risk of service degradation during traffic volatility.
- Global Standardization: By supporting this across Fargate, Managed Instances, and EC2, AWS ensures that no matter the compute model, the scaling behavior remains consistent and predictable.
Future Outlook: The Path Toward Autonomous Infrastructure
As we look toward the future, the integration of 20-second metrics is likely only the beginning. We can anticipate that AWS will continue to leverage its machine learning capabilities to further optimize the "decision-making" layer of the auto-scaler.
The current update sets a new baseline for the industry. As competitors scramble to match this level of responsiveness, AWS users are already benefiting from a system that is becoming increasingly "intelligent." The transition from human-managed capacity to autonomous, self-healing, and self-scaling infrastructure is moving at an accelerated pace, and with this latest release, AWS has firmly secured its position at the forefront of that movement.
For engineers currently managing ECS clusters, the call to action is clear: evaluate your current scaling policies, identify the workloads that suffer from traffic volatility, and begin migrating your high-priority services to the new high-resolution metric standard. The infrastructure of tomorrow is being built today, and it is faster than ever before.
